If I were the Register I would have titled this: Raging Stuffed Elephant To Devour Two Warehouse Vendors… I love the Register… if you do not read it have a look…
This is a post is about the market implications of architecture…
Let us assume that Hadoop matures and finds a permanent place in the market. This is not certain with some folks expressing concern (here) and others boundless enthusiasm (here). So let’s assume… and consider where it might fit.
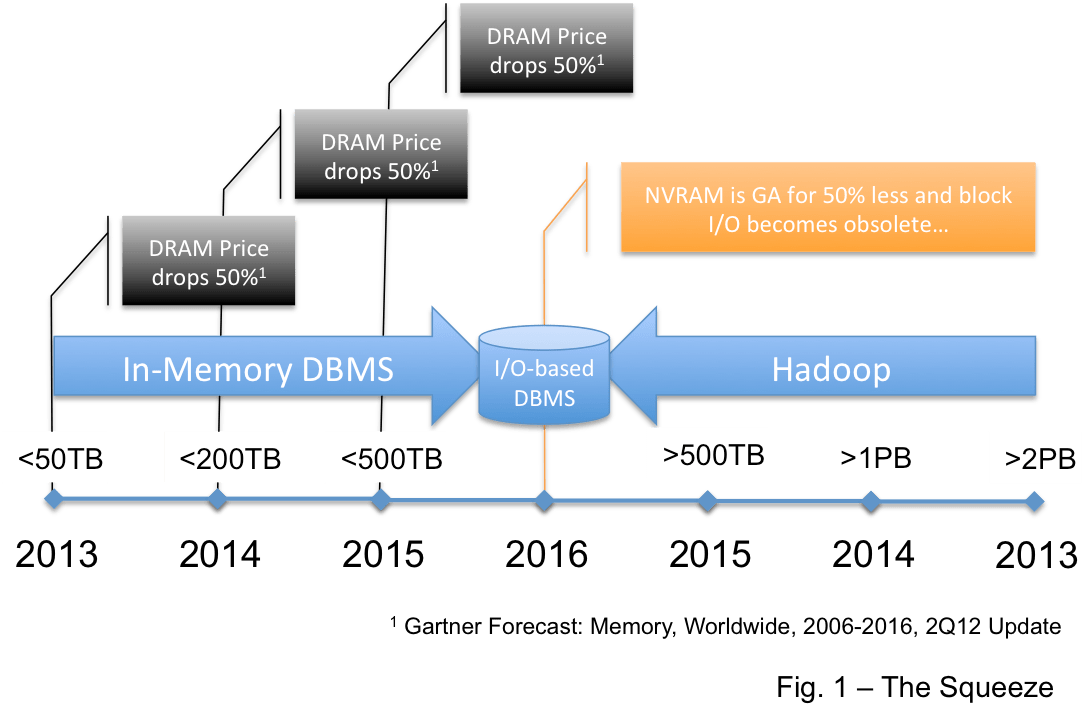 One place is in the data warehouse market… This view says Hadoop replaces the DBMS for data warehouses. But the very mature BI/DW market requires a high level of operational integrity and Hadoop is not there yet… it is advancing rapidly as an enterprise platform and I believe it will get there… but it will be 3-4 years. This is the thinking I provided here that leads me to draw the picture in Figure 1.
One place is in the data warehouse market… This view says Hadoop replaces the DBMS for data warehouses. But the very mature BI/DW market requires a high level of operational integrity and Hadoop is not there yet… it is advancing rapidly as an enterprise platform and I believe it will get there… but it will be 3-4 years. This is the thinking I provided here that leads me to draw the picture in Figure 1.
It is not that I believe that Hadoop will consume the data warehouse market but I believe that very large EDW’s… those over 1PB… and maybe over 500TB will be compelled by the economics of “free” to move big warehouses to Hadoop. So Hadoop will likely move down into the EDW space from the top.
Another option suggests that Big Data will be a platform unto itself. In this view Hadoop will sit beside the existing BI/DW platform and feed that platform the results of queries that derive structure from unstructured data… and/or that aggregate Big Data into consumable chunks. This is where Hadoop sits today.
In data warehouse terms this positions Hadoop as a very large independent analytic data mart. Figure 2 depicts this. Note that an analytics data mart, and a Hadoop cluster, require far less in the way of operational infrastructure… they share very similar technical requirements.
This leads me to the point of this post… if Hadoop becomes a very large analytic data mart then where will Greenplum and Netezza fit in 2-3 years? Both vendors are positioning themselves in the analytic space… Greenplum almost exclusively so. Both vendors offer integrated Hadoop products… Greenplum offers the Greenplum database and Hadoop in the same hardware cluster (see here for their latest announcement)… Netezza provides a Hadoop connector (here). But if you believe in Hadoop… as both vendors ardently do… where do their databases fit in the analytics space once Hadoop matures and fully supports SQL? In the next 3-4 years what will these RDBMSs offer in the big data analytics space that will be compelling enough to make the configuration in Figure 3 attractive?
 I know that today Hadoop cannot do all that either Netezza or Greenplum can do. I understand that Netezza has two positions in the market… as an analytic appliance and as a data mart appliance… so it may survive in the mart space. But the overlap of technical requirements between Hadoop and an analytic data mart… combined with the enormous human investment in Hadoop R&D, both in the core and in the eco-system… make me wonder about where “Big Data” analytic relational databases will fit?
I know that today Hadoop cannot do all that either Netezza or Greenplum can do. I understand that Netezza has two positions in the market… as an analytic appliance and as a data mart appliance… so it may survive in the mart space. But the overlap of technical requirements between Hadoop and an analytic data mart… combined with the enormous human investment in Hadoop R&D, both in the core and in the eco-system… make me wonder about where “Big Data” analytic relational databases will fit?
Note that this is not a criticism of the Greenplum RDBMS. Greenplum is a very fine product, one of the best EDW platforms around. I’ll have more to say about it when I provide my 2 Cents… But if Figure 2 describes the end state for analytics in 2-3 years then where is the place for the Figure 3 architecture? If Figure 3 is the end state then I do not see where the line will be drawn between the analytic workload that requires Greenplum and that that will run on Hadoop? I barely can see it now… and I cannot see it at all in the near future.
Both EMC Greenplum and IBM seem to strongly believe in Hadoop… they must see the overlap in functionality and feel the market momentum of Hadoop. They must see, better than most, that Hadoop wins this battle.
Regards,
Ed
I don’t get where and how Hadoop will solve all the BI workload anytime soon. It’s complicated today for the staff to write SQL queries – but this is somehow manageable. I don’t believe that companies will hire even more programmers to solve their workload (and write MapReduce) – it has to go the other direction.
Yes, there is HiveQL (and other libraries), but they don’t solve the problem which I mentioned above. And running SQL (remember: STRUCTURED query language) on top of Hadoop will for sure not improve your performance and make writing code more easy.
I agree that today Hadoop would not handle a BI workload, Andreas… completely agree. But it will solve for data science apps… and that makes is an analytic data store.
I think if you look to Impala… and a raft of announcements coming around better SQL support for the Hadoop ecosystem… you will see that SQL is the easy part. There is no architectural impediment to improved Hadoop performance… and there is more R&D, both commercial and open source, going into this space than into any three commercial RDBMS products. It will catch up.
We can debate over the definition of “anytime soon”… but I am saying 2015… and I think that is a very safe bet…
Rob
I did mention SQL, but merely as a placeholder for “someone has to do the coding” – and SQL makes it more (or less) easy to write queries, compared to MapReduce. The moment you move this workload into “the engine” (might it be Impala or something different) you also need a good planner how to execute these queries. Which, in my opinion, is the complicated part here. Not sure if two or three years are enough to catch up with other products.
One thing you and I discussed in the past is the non-existent real-time capability of Hadoop. Impala and Dremel address this problem. That’s good. And that’s easily doable, way before 2015. It was a real burden in my opinion that Hadoop had no real-time capabilities right from the beginning.
Finally there’s optimization: if you talk about this BI workload from data warehouses, I’m not sure how you will perform better without optimization (in the planner and in the data). Right now, Hadoop under the hood has to repeat all the steps over and over again, across all the data. I’m looking forward to see the improvements coming down this road.
It is easy Andreas… Hadoop will just copy the optimizer from PostgreSQL. 🙂 (For the general reader… Andreas is on the PostgreSQL BOD)…
Nicely put Rob. I tend to agree with your rationale. Hadoop promises a lot as it becomes a commodity platform. It’ll be telling once the big SI vendors start adopting it and really pushing it in their client base.
Why are only Greenplum and Netezza in Hadoop’s sights? Surely the same same rationale applies to Aster, Exadata, Vertica, MS PDW et al?
My thinking for some time has been that a lot of folks are going to go from a standard SMP+DBMS+SAN/NAS straight to Hadoop and bypass the MPP DBMS option altogether.
As Teradata is the only well established MPP DBMS vendor, in terms of installed production base, surely it follows that Hadoop is a potential threat to all of the less well established players in the space?
In our company, we replaced netezza with hadoop. The performance is quite satisfactory. Netezza has around 52 SPUS and hadoop has 12 datanodes. If the number of data nodes are increased, definately hadoop will beat netezza performance.
Wow, Ram. That is impressive. Are you using MapReduce? Hive? Is it an analytics use case?