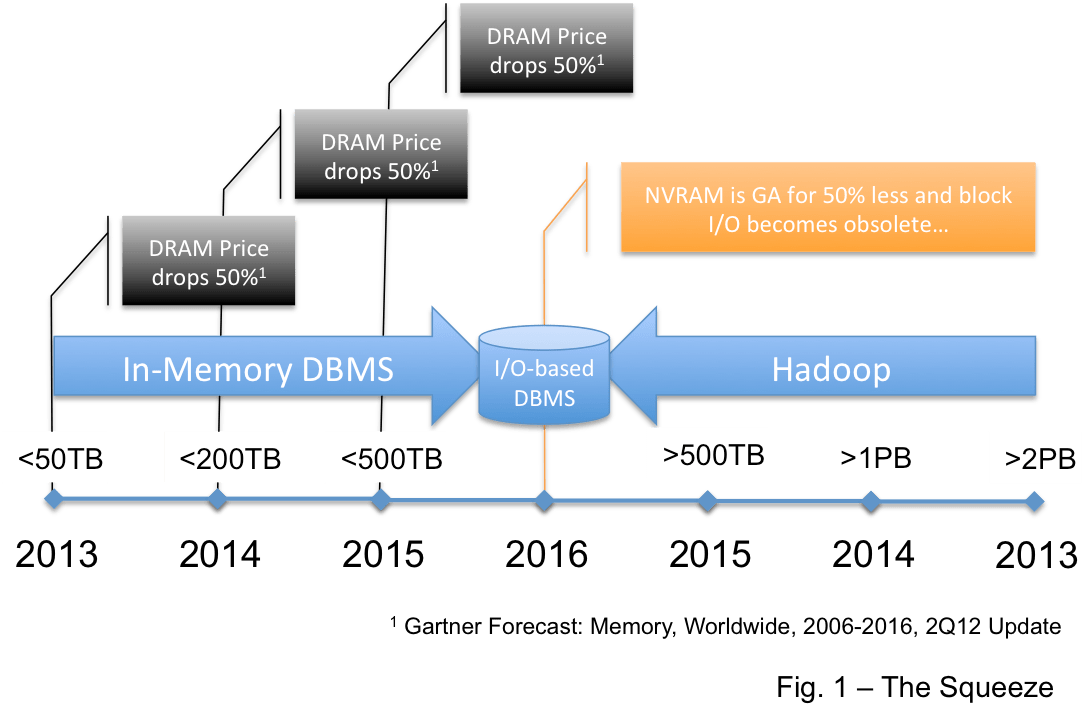
If the Gartner estimates here are correct… then DRAM prices will fall 50% per year per year over the next several years… and then in 2015 non-volatile RAM (see the related articles below) will become generally available.
It has been suggested that memory prices will fall slower than data warehouses will grow (see here). That does not seem to be the case… and the combination of cheaper memory and then non-volatile memory will make in-memory databases like SAP HANA ever more compelling. In fact, as I predicted… and to their credit, Teradata is adding more memory (see here).
If you missed the tweet… 2+ years ago I predicted here that Teradata would go away from ByNet… and lo and behold they did (see here).
In the same post I predicted that Netezza would go away from FPGAs. This has not come to pass. But I wonder if it might… or if there is a bigger change possible?
With the recent announcements of DB2 BLU and column store I suspect that DB2 will outperform Netezza when the query mix does not fall directly in Netezza’s sweet spot.
I also have a suspicion that the Netezza architecture, with its execution engine split across two different processors, is just hard to engineer. I cannot think of another reason features come so slowly there. Why, for example, is there no columnar support? Greenplum built it on the same Postgres base with less than a handful of engineers in a year. Teradata now offers columnar tables as well.
These concerns… combined with some previous notes on Netezza add up as follows:
FPGAs no longer provide a performance advantage (per my link above)
FPGAs limit the ability of the DBMS to use more cores (see here)
FPGAs limit the ability of the DBMS to manage workload (see here… and especially the comments)
FPGAs and having a 2-phase split execution environment limits the ability to extend and enhance the code base (a new conjecture)
Zone Maps and CBTs provide a limited ability to solve for a wide range of queries… they are just an index (see here)
DB2 Column Store provides a performance boost equal to or greater than zone maps and CBTs (a new conjecture)
DB2 BLU provides a performance boost well in excess of what Netezza can provide (see here)
The Netezza architecture with FPGAs provided a distinct advantage in 2000 when CPU was the scarce commodity. But multi-core systems and the advance of Moore’s Law soon made processing abundant… and the advantage of FPGA co-processing diminished. Without a distinct advantage the split execution architecture became a disadvantage… and the complexity of that design kept Netezza from developing the advances on top of the Postgres base that were very easy to develop by others.
Architecture counts… and DB2 is a strong product. If, as I suspect, DB2 is now a more capable product than Netezza… I wonder what path IBM may take?
In the post here I listed the units of parallelism (UoP) applied by various products on a single node. Those findings are summarized in the table below.
Product
Version/HW
Cores per Node
UoP per Node
Notes
Teradata
EDW 6700H
16
32
Uses hyper-threads.
Greenplum
DCA UAP Edition
16
8
Recommends 1 Segment for each 2 cores. Maybe some multi-threading per query so it could be greater than 8 on the average… and could be 16 with hyper-threads… but not more than 32 for sure.
Exadata
X3
12
12-24
Maybe only 12… cannot find if they use hyper-threads.
A UoP is defined as the maximum number of instructions that can execute in parallel on a single node for a single query. Note that in the comments there was a lively debate where some readers wanted to count threads or processes or slices that were “active” but in a wait state. Since any program can start threads that wait I do not count these as UoP (later we might devise a new measure named units of waiting that would gauge the inefficiency in any given design by measuring the amount of waiting around required to keep the CPUs fed… maybe the measure would be valuable in measuring the inefficiency of the queue at your doctor’s office or at any government agency).
On some CPUs vendors such as Intel allow two threads to execute instructions in-parallel in a core. This is called hyper-threading and, if implemented, it allows for two UoP on a single core. Rather than constantly qualify the statements for the rest of this blog when I refer to cores I mean to imply hyper-threads.
The lively comments in the blog included some discussion of the sort of techniques used by vendors to try and keep the cores in the CPU on each node fed. It is these techniques that lead to more active I/O streams than cores and more threads than cores.
For several years now Intel and the other CPU manufacturers have been building ever more cores into their products. This has allowed them to continue the trend known as Moore’s Law. Multi-core is now a fact of life and even phones, tablets, and personal computers have multi-core chips.
But if you look at the table you can see that the database products above, even the newly announced products from Teradata and Netezza, are using CPUs with relatively few cores. The high-end Intel processors have 40 cores and the databases, with the exception of HANA, use Intel products with at most 16 cores. Further, Intel will deliver Ivy Bridge processors to the market this year with 120 cores. These vendors know this… yet they have chosen to deliver appliances with the previous generation CPUs. You might ask why?
I believe that there is an architectural reason for this (also a marketing reason covered here).
It is very hard to keep 80 cores fed with data when you have to perform block I/O. It will be nearly impossible to keep the 240 cores coming with Ivy Bridge fed. One solution is to deploy more nodes in a shared-nothing configuration with fewer cores per node… but this will be expensive requiring more power, floorspace, administration, etc. This is the solution taken by most of the vendors above. Another solution is to solve the problem without I/O with an in-memory database (IMDB) architecture. This is the solution taken by SAP with HANA.
Intel, IBM, and the rest will continue to build out using the multi-core approach for the foreseeable future. IMDB products will be able to fully utilize this product. Other products will struggle to take full advantage as we can see already… they will adapt and adjust and do what they can… but ultimately IMDB will win, I think… because there is just no other way to keep up as Moore’s Law continues to drive technology… no other way to feed the CPU engines with data fast enough.
If I am right then you will see more IMDB offerings from more vendors, including from the major vendors in the near future (note that this does not include the announcements of “database in memory” from Oracle which is not by any measure an in-memory database).
This is the underlying reason why Donald Feinberg (and Timo Elliott) are right on here. Every organization will be running in-memory… and soon.
6 May… There is a good summary of this post and on the comments here. – Rob
17 April… A single unit of parallelism is a core plus a thread/process to feed it instructions plus a feed of data. The only exception is when the core uses hyper-threading… in which case 2 instructions can execute more-or-less at the same time… then a core provides 2 units of parallelism. All of the other stuff: many threads per core and many data shards/slices per thread are just techniques to keep the core fed. – Rob
16 April… I edited this to correct my loose use of the word “shard”. A shard is a physical slice of data and I was using it to represent a unit of parallelism. – Rob
I made the observation in this post that there is some inefficiency in an architecture that builds parallel streams that communicate on a single node across operating system boundaries… and these inefficiencies can limit the number of parallel streams that can be deployed. Greenplum, for example, no longer recommends deploying a segment instance per core on a single node and as a result not all of the available CPU can be applied to each query.
This blog will outline some other interesting limits on the level of parallelism in several products and on the definition of Massively Parallel Processing (MPP). Note that the level of parallelism is directly associated with performance.
On HANA a thread is built for each core… including a thread for each hyper-thread. As a result HANA will split and process data with 80 units of parallelism on a high-end 40-core Intel server.
Exadata deploys 12 cores per cell/node in the storage subsystem. They deploy 12 disk drives per node. I cannot see it clearly documented how many threads they deploy per disk… but it could not be more than 24 units of parallelism if they use hyper-threading of some sort. It may well be that there are only 12 units of parallelism per node (see here).
Updated April 16: Netezza deploys 8 “slices” per S-Blade… 8 units of parallelism… one for each FPGA core in the Twin times four (2X4) Twinfin architecture (see here). The next generation Netezza Striper will have 16-way parallelism per node with 16 Intel cores and 16 FPGA cores…
Updated April 17: Teradata uses hyper-threading (see here)… so that they will deploy 24 units of parallelism per node on an EDW 6700C (2X6X2) and 32 units of parallelism per node on an EDW 6700H (2X8X2).
You can see the different definitions of the word “massive” in these various parallel processing systems.
Note that the next generation of Xeon processors coming out later this year will have 8X15 processors or 120 cores on a fat node:
This will provide HANA with the ability to deploy 240 units of parallelism per node.
Netezza will have to find a way to scale up the FPGA cores per S-Blade to keep up. TwinFin will have to become QuadFin or DozenFin. It became HexadecaFin… see above. – Rob
Exadata will have to put 120 SSD/disk drive combos in each node instead of 12 if they want to maintain the same parallelism-to-disk ratio with 120 units of parallelism.
Teradata will have to find a way to get more I/O bandwidth on the problem if they want to deploy nodes with 120+ units of parallelism per node.
Most likely all but HANA will deploy more nodes with a smaller number of cores and pay the price of more servers, more power, more floor space, and inefficient inter-node network communications.
The following performance numbers are being reported publicly for HANA:
HANA scans data at 3MB/msec/core
On a high-end 80-core server this translates to 240GB/sec per node
HANA inserts rows at 1.5M records/sec/core
Or 120M records/sec per node…
Aggregates 12M records/sec/core
Or 960M records per node…
These numbers seem reasonable:
A 100X improvement over disk-based scan (The recent EMC DCA announcement claimed 2.4GB/sec per node for Greenplum)…
Sort of standard OLTP insert speeds for a big server…
Huge performance gains for in-memory aggregation using columnar orientation and SIMD HPC instructions…
Note that these numbers are the basis for suggesting that there is a new low-TCO approach to BI that eliminates aggregate tables, materialized views, cubes, and indexes… and eliminates the operational overhead of computing these artifacts… and still provides a sub-second response for all queries.
If Greenplum HAWQ does not look promising (see my previous posts on HAWQ here and here) what are the prospects for TeradataAster Data… which aspires to both replace and/or co-exist with Hadoop for a fee? Teradata+Hadoop maybe… but Teradata+Aster+Hadoop seems like one layer too many… as does Aster+Hadoop.
(OK, I removed the bad “HAWQing” pun in the title… no complaints from readers… it just seemed unfair… – Rob)
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
From a technical perspective, Greenplum is my favorite data warehouse database. Built on the same architecture as Teradata (see here), the Greenplum team was able to extend the core of Postgres… first building out a shared-nothing architecture and then adding feature after feature… putting the heat on the other major players. Greenplum was the first row-based RDBMS to add full columnar support… and their data-loading capability is second-to-none.
Oddly they do not want to be in the data warehouse space. Their recent announcement (here) does not include any reference to data warehousing or business intelligence. The tweets from @Greenplum, the Greenplum website, and all things marketing are focussed on analytics and/or Hadoop. Even their page on data warehousing (here) has no articles on data warehousing. It is just not their target market. That is fine… the product is still a great EDW platform… but it is a worry.
Where They Win
The reason they target analytics is because they excel there. If your warehouse workload clogs because of big, complex, queries… Greenplum can win the day. Their data flow architecture, which keeps tuples moving from execution step to execution step without writing to spool provides them with the ability to beat the competition on analytics. They provide a very rich set of in-database analytics and some add-on capabilities to improve the productivity of your data scientist team.
Their data load architecture, which they call scatter-gather, is a big differentiator. If your problem is that you cannot get data loaded and reports out in your nightly batch window then the combination of scatter-gather and the ability to run big report queries is unbeatable.
Greenplum also has a unique solution for near-real-time. They marry Gemfire, an in-memory object-oriented database, with scatter-gather to move small batches of inserted data to Greenplum with a very small time delta. I do not believe this solution supports inserts or deletes as they have to be applied directly to the Greenplum database… but it is a nice capability for a certain class of problems.
Where They Lose
Greenplum, like Teradata, can be beat when the problem to be solved is narrow. In these cases, when the database supports a single application with a small number of queries or when it supports a narrowly focussed data mart, they are vulnerable to Netezza, Vertica, or even Exadata. It is also sometimes the case that a poorly designed POC can narrow the scope enough that Greenplum loses.
Greenplum can also lose when a full EDW is required. The basic architecture of the RDBMS is capable of supporting an EDW… but some of the operational features required… RASR, workload, incremental backup, etc. are not mature. This may well be the intentional result of their focus away from these features at analytics.
In the Market
Despite the worries Greenplum should be included in every POC. They will push Teradata hard in performance and in price/performance.
As noted here… I do not understand their market strategy. It seems that they are competing with themselves by offering Hadoop for analytics… but this cannot be a bad thing for customers even if it is an odd position in the market. The analytics market they favor is tough… relatively small (compared to the DW space)… emerging… there are several capable competitors… and the market is haunted by the same problem that killed the data mining market in the mid-1990’s… there are just not enough skilled data scientists (see here).
My Guess at the Future
I cannot guess at the future of Greenplum… They are being moved into a new business unit that could be spun into a new company that has a charter to build software for the cloud (see here). This is odd in several dimensions. First, as I noted here, the shared nothing architecture Greenplum is built on is not a perfect fit for the cloud. There are ways to get around this (maybe the topic for a future post?) but it will require development in a fundamentally new direction. Further, the new division seems to be a software-only venture. This makes the future of the EMC Greenplum Data Computing Appliance uncertain. I suppose that there will be announcements soon to clarify these questions… but the architectural disconnects make it likely that there will be some arm-waving for a while.
The TwinFin Surf Board (Photo credit: tvanhoosear)
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
Netezza put a new spin on data warehousing… they made it easy. The Netezza software includes a unique clustered index feature called a zone map that is powerful and easy to use. They also use a FPGA co-processor to augment the CPUs, offloading data compression and projection. When both of these innovations combine Netezza is hard to beat.
Zone maps are powerful when they can be used in a query plan… but the hardware is only good, not great, when zone maps are not in the plan. FPGAs provided a huge boost when Netezza first came on the scene… but as discussed here they do not provide the same boost today. In addition, FPGAs may limit the ability of a Netezza cluster to handle concurrent queries (see here and especially the comments).
The IBM acquisition has opened up a market of Blue shops to Netezza… so they are selling… and as a result Netezza is here to stay.
Where They Win
Of course, Netezza will win in all-Blue shops.
Netezza wins when there is a naturally sequenced field in each big table that is also used in the predicate for most queries. For example, if data is naturally in date/time sequence and every query has a date/time constraint then Netezza is hard to beat. This is the case most often for focussed data marts or single application databases… so look for Netezza for these sort of problems.
Netezza wins when there are a relatively small number of concurrent queries… and they can win when the queries are complex… as long as the zone map is in the plan.
Netezza can win when the POC is designed such that zone maps may be used in the POC… for example when the POC models only a single data load and the data is pre-sorted… even when the real application would fragment the data (for example… data will not naturally enter the warehouse sequentially by customer number… the same customer will be represented time and again… but if you load once only for a POC then you can sort by customer number and use it in the query predicates).
Note that I am not saying that Netezza is a poor performer when zone maps are not used… it is good… but they would never win a POC if no queries used the zone map.
Where They Lose
Guess what? Netezza loses when the zone maps cannot be used or can be used for only a small fraction of the query workload. Note again that the use of a zone map depends on two factors: the data has to be in sequence over all time, and the queries must use the columns mapped in the predicate. If data enters the system out of sequence then the zone map fragments and eventually loses the ability to speed up queries (a few random out of sequence rows are OK).
This constraint makes it hard for Netezza to service data warehouses where, by definition, lots of different user constituencies come at the data from lots of different directions… rather than always using the path grooved with a zone map.
Netezza was designed when only Sybase IQ had columnar oriented tables… today columnar is in nearly every DW database and this allowed the competition to cut deeply into Netezza’s competitive, zone-map enabled, edge. Teradata columns, Greenplum columns, or the natural column stores can win even when zone maps are on target.
Bottom line: do a POC…
In the Market
I spend most of my time in the general market for data warehousing. You won’t see me offer much of an opinion on HANA for BW, for example… even though there are ten thousand plus BW warehouses I just do not see them in the places I work.
Before Netezza was acquired by IBM they were everywhere… in nearly every POC. Now… not so much. To a very large extent they seem to have been directed into the Blue-only customer base (now that I think about it the same thing happened to the Ascential Data Stage suite of ETL products).
My Guess at the Future
As I noted in the reference above… I think that Netezza will eventually go away from the co-processor strategy.
There have been rumors for several years of design that allowed multiple zone maps. This would be very important… but loading out-of-sequence data, which is the necessary the result, could be very slow.
Netezza has lost some of its edge as other technologies added columnar capabilities to their technologies… and Netezza is surely looking at this… but their architecture which includes an execution engine on the server and on the FPGA makes this more complex than you might suspect. Zone maps and two-stage optimization (one in the server and once in the FPGA) is cool… but a tight coupling of the tricks makes for a difficult time extending and adding new features.
If I were the King of Netezza and I could not find a reasonable way to extend beyond the two tricks that got me here I would go with the flow… I would position Netezza as an extremely easy-to-deploy data mart appliance and hook it tightly (i.e. build in some integration) along-side DB2 and Hadoop… and I would cede the EDW space to DB2 and the Big Data space to Hadoop.
Next up… my 2 Cents on Greenplum
May 1, 2013: Here is an update, or maybe a summary, of my view on Netezza… – Rob
If I were the Register I would have titled this: Raging Stuffed Elephant To Devour Two Warehouse Vendors… I love the Register… if you do not read it have a look…
This is a post is about the market implications of architecture…
Let us assume that Hadoop matures and finds a permanent place in the market. This is not certain with some folks expressing concern (here) and others boundless enthusiasm (here). So let’s assume… and consider where it might fit.
One place is in the data warehouse market… This view says Hadoop replaces the DBMS for data warehouses. But the very mature BI/DW market requires a high level of operational integrity and Hadoop is not there yet… it is advancing rapidly as an enterprise platform and I believe it will get there… but it will be 3-4 years. This is the thinking I provided here that leads me to draw the picture in Figure 1.
It is not that I believe that Hadoop will consume the data warehouse market but I believe that very large EDW’s… those over 1PB… and maybe over 500TB will be compelled by the economics of “free” to move big warehouses to Hadoop. So Hadoop will likely move down into the EDW space from the top.
Another option suggests that Big Data will be a platform unto itself. In this view Hadoop will sit beside the existing BI/DW platform and feed that platform the results of queries that derive structure from unstructured data… and/or that aggregate Big Data into consumable chunks. This is where Hadoop sits today.
In data warehouse terms this positions Hadoop as a very large independent analytic data mart. Figure 2 depicts this. Note that an analytics data mart, and a Hadoop cluster, require far less in the way of operational infrastructure… they share very similar technical requirements.
This leads me to the point of this post… if Hadoop becomes a very large analytic data mart then where will Greenplum and Netezza fit in 2-3 years? Both vendors are positioning themselves in the analytic space… Greenplum almost exclusively so. Both vendors offer integrated Hadoop products… Greenplum offers the Greenplum database and Hadoop in the same hardware cluster (see here for their latest announcement)… Netezza provides a Hadoop connector (here). But if you believe in Hadoop… as both vendors ardently do… where do their databases fit in the analytics space once Hadoop matures and fully supports SQL? In the next 3-4 years what will these RDBMSs offer in the big data analytics space that will be compelling enough to make the configuration in Figure 3 attractive?
I know that today Hadoop cannot do all that either Netezza or Greenplum can do. I understand that Netezza has two positions in the market… as an analytic appliance and as a data mart appliance… so it may survive in the mart space. But the overlap of technical requirements between Hadoop and an analytic data mart… combined with the enormous human investment in Hadoop R&D, both in the core and in the eco-system… make me wonder about where “Big Data” analytic relational databases will fit?
Note that this is not a criticism of the Greenplum RDBMS. Greenplum is a very fine product, one of the best EDW platforms around. I’ll have more to say about it when I provide my 2 Cents… But if Figure 2 describes the end state for analytics in 2-3 years then where is the place for the Figure 3 architecture? If Figure 3 is the end state then I do not see where the line will be drawn between the analytic workload that requires Greenplum and that that will run on Hadoop? I barely can see it now… and I cannot see it at all in the near future.
Both EMC Greenplum and IBM seem to strongly believe in Hadoop… they must see the overlap in functionality and feel the market momentum of Hadoop. They must see, better than most, that Hadoop wins this battle.
Here is a true story… fuzzed just a little to disguise the real-life characters…
Three years ago… a friend calls to say: “Our new CxO just informed us that we needed to install a 1000-node Hadoop cluster in the next two months. I said… cool, what is the use case? He says… don’t argue with me… just get 1000 nodes up and running in the next 60 days. I say: there is no floorspace or power for that large a system. He says: do it in the next 60 days!”
My friend then decommissioned several systems that were doing productive, but expendable work, and installed 1000 nodes of Hadoop. And it sat there with no business problem to solve.
Today there is a little work running on the cluster… adding far less value than the expendable work that was decommissioned. The CxO is gone… with a glowing resume that says that he deployed one of the World’s largest Hadoop clusters.
When the hype over a technology gets so amplified that the hypers start hyping about the level of the hype… Hype-squared… you know that disillusionment cannot be far behind. Gartner is pretty spot on with their Hype Cycle (see here)… but Hadoop may survive, methinks.
Readers… any other good Hadoop hype stories to share?