A reader recently wrote to me and asked about Netezza: “why does everyone insist that these (zone maps) tell you where ‘not to look’ when hunting for data?”. I’ll provide a direct answer… and a more meaningful answer.
Imagine that you have a list of data blocks with some metadata for each block that tells you the range of data in each block for a given column: FOO as follows:
Block 1: FOO 0-173
Block 2: FOO 174-323
Block 3: FOO 324-500
and a query that selects WHERE FOO=42.
If Netezza scanned the metadata and sent its read routine the list of blocks to not read… it would send 2,3. This is clearly not the case… if there are a million blocks it would not send a list of 999999 block numbers to not read… and force the read routine to figure out what was left to read. So clearly Netezza does not really tell you where ‘not to look’. This is a clever turn-of-phrase.
But I like this particular cleverness. Every DBMS is built with features designed to avoid I/O:
indexes are metadata that point to blocks to reduce reading unnecessary blocks;
partitions contain metadata to reduce reading unnecessary partitions;
column stores are designed to reduce reads of unnecessary columns; and
caches hold hot data blocks to avoid re-reading those blocks.
In fact, the highest performance DBMS will almost always be the one that most effectively minimizes I/O. This is why in-memory databases always have the highest performance.
So while zone maps do not really tell the system directly what not to read… the effect is ‘not to look’ at unnecessary data.
I wondered here how IBM would position DB2 with BLU versus Netezza. Please have a look before you go on… and let me admit here and now that when I wrote this I chickened out. As I sat down this time I became convinced that I should predict the end of Netezza.
Why?
In the post here Bob Picciano, the general manager of IBM’s Information Management Software Division, made it nearly clear. He said that DB2 BLU is for systems “under 50 terabytes” only because BLU does not cluster. I suspect that if IBM converted all of the Netezza clusters with under 50TB of data to BLU it would knock out 70% or more of the Netezza install base. He states that “most data warehouses are in the under-10-terabyte range”… and so we can assume that Netezza, precluded from anything under 50TB, has a relatively small market left. He suggests that Netezza is for “petabyte-size collections”… but as I suggested here (check out the picture!), Hadoop is going to squeeze the top away from Netezza… while in-memory takes away the bottom… and IBM is very much into Hadoop so the take-away will not require a fight. Finally, we can assume, I think, that the BLU folks are working on a clustered version that will eat more from the bottom of Netezza’s market.
We should pay Netezza some respect as it fades. When they entered the market Teradata was undisputed. Netezza did not knock out the champ but, for the first time, they proved that it was possible to stay in the ring… and this opened the market for Exadata, Greenplum, Vertica and the rest.
If you missed the tweet… 2+ years ago I predicted here that Teradata would go away from ByNet… and lo and behold they did (see here).
In the same post I predicted that Netezza would go away from FPGAs. This has not come to pass. But I wonder if it might… or if there is a bigger change possible?
With the recent announcements of DB2 BLU and column store I suspect that DB2 will outperform Netezza when the query mix does not fall directly in Netezza’s sweet spot.
I also have a suspicion that the Netezza architecture, with its execution engine split across two different processors, is just hard to engineer. I cannot think of another reason features come so slowly there. Why, for example, is there no columnar support? Greenplum built it on the same Postgres base with less than a handful of engineers in a year. Teradata now offers columnar tables as well.
These concerns… combined with some previous notes on Netezza add up as follows:
FPGAs no longer provide a performance advantage (per my link above)
FPGAs limit the ability of the DBMS to use more cores (see here)
FPGAs limit the ability of the DBMS to manage workload (see here… and especially the comments)
FPGAs and having a 2-phase split execution environment limits the ability to extend and enhance the code base (a new conjecture)
Zone Maps and CBTs provide a limited ability to solve for a wide range of queries… they are just an index (see here)
DB2 Column Store provides a performance boost equal to or greater than zone maps and CBTs (a new conjecture)
DB2 BLU provides a performance boost well in excess of what Netezza can provide (see here)
The Netezza architecture with FPGAs provided a distinct advantage in 2000 when CPU was the scarce commodity. But multi-core systems and the advance of Moore’s Law soon made processing abundant… and the advantage of FPGA co-processing diminished. Without a distinct advantage the split execution architecture became a disadvantage… and the complexity of that design kept Netezza from developing the advances on top of the Postgres base that were very easy to develop by others.
Architecture counts… and DB2 is a strong product. If, as I suspect, DB2 is now a more capable product than Netezza… I wonder what path IBM may take?
The TwinFin Surf Board (Photo credit: tvanhoosear)
Since my blogs tend to be in response to some stimulus they may not reflect a holistic view on any particular product. The “My 2 Cents” series will try to provide a broader view…
Netezza put a new spin on data warehousing… they made it easy. The Netezza software includes a unique clustered index feature called a zone map that is powerful and easy to use. They also use a FPGA co-processor to augment the CPUs, offloading data compression and projection. When both of these innovations combine Netezza is hard to beat.
Zone maps are powerful when they can be used in a query plan… but the hardware is only good, not great, when zone maps are not in the plan. FPGAs provided a huge boost when Netezza first came on the scene… but as discussed here they do not provide the same boost today. In addition, FPGAs may limit the ability of a Netezza cluster to handle concurrent queries (see here and especially the comments).
The IBM acquisition has opened up a market of Blue shops to Netezza… so they are selling… and as a result Netezza is here to stay.
Where They Win
Of course, Netezza will win in all-Blue shops.
Netezza wins when there is a naturally sequenced field in each big table that is also used in the predicate for most queries. For example, if data is naturally in date/time sequence and every query has a date/time constraint then Netezza is hard to beat. This is the case most often for focussed data marts or single application databases… so look for Netezza for these sort of problems.
Netezza wins when there are a relatively small number of concurrent queries… and they can win when the queries are complex… as long as the zone map is in the plan.
Netezza can win when the POC is designed such that zone maps may be used in the POC… for example when the POC models only a single data load and the data is pre-sorted… even when the real application would fragment the data (for example… data will not naturally enter the warehouse sequentially by customer number… the same customer will be represented time and again… but if you load once only for a POC then you can sort by customer number and use it in the query predicates).
Note that I am not saying that Netezza is a poor performer when zone maps are not used… it is good… but they would never win a POC if no queries used the zone map.
Where They Lose
Guess what? Netezza loses when the zone maps cannot be used or can be used for only a small fraction of the query workload. Note again that the use of a zone map depends on two factors: the data has to be in sequence over all time, and the queries must use the columns mapped in the predicate. If data enters the system out of sequence then the zone map fragments and eventually loses the ability to speed up queries (a few random out of sequence rows are OK).
This constraint makes it hard for Netezza to service data warehouses where, by definition, lots of different user constituencies come at the data from lots of different directions… rather than always using the path grooved with a zone map.
Netezza was designed when only Sybase IQ had columnar oriented tables… today columnar is in nearly every DW database and this allowed the competition to cut deeply into Netezza’s competitive, zone-map enabled, edge. Teradata columns, Greenplum columns, or the natural column stores can win even when zone maps are on target.
Bottom line: do a POC…
In the Market
I spend most of my time in the general market for data warehousing. You won’t see me offer much of an opinion on HANA for BW, for example… even though there are ten thousand plus BW warehouses I just do not see them in the places I work.
Before Netezza was acquired by IBM they were everywhere… in nearly every POC. Now… not so much. To a very large extent they seem to have been directed into the Blue-only customer base (now that I think about it the same thing happened to the Ascential Data Stage suite of ETL products).
My Guess at the Future
As I noted in the reference above… I think that Netezza will eventually go away from the co-processor strategy.
There have been rumors for several years of design that allowed multiple zone maps. This would be very important… but loading out-of-sequence data, which is the necessary the result, could be very slow.
Netezza has lost some of its edge as other technologies added columnar capabilities to their technologies… and Netezza is surely looking at this… but their architecture which includes an execution engine on the server and on the FPGA makes this more complex than you might suspect. Zone maps and two-stage optimization (one in the server and once in the FPGA) is cool… but a tight coupling of the tricks makes for a difficult time extending and adding new features.
If I were the King of Netezza and I could not find a reasonable way to extend beyond the two tricks that got me here I would go with the flow… I would position Netezza as an extremely easy-to-deploy data mart appliance and hook it tightly (i.e. build in some integration) along-side DB2 and Hadoop… and I would cede the EDW space to DB2 and the Big Data space to Hadoop.
Next up… my 2 Cents on Greenplum
May 1, 2013: Here is an update, or maybe a summary, of my view on Netezza… – Rob
If I were the Register I would have titled this: Raging Stuffed Elephant To Devour Two Warehouse Vendors… I love the Register… if you do not read it have a look…
This is a post is about the market implications of architecture…
Let us assume that Hadoop matures and finds a permanent place in the market. This is not certain with some folks expressing concern (here) and others boundless enthusiasm (here). So let’s assume… and consider where it might fit.
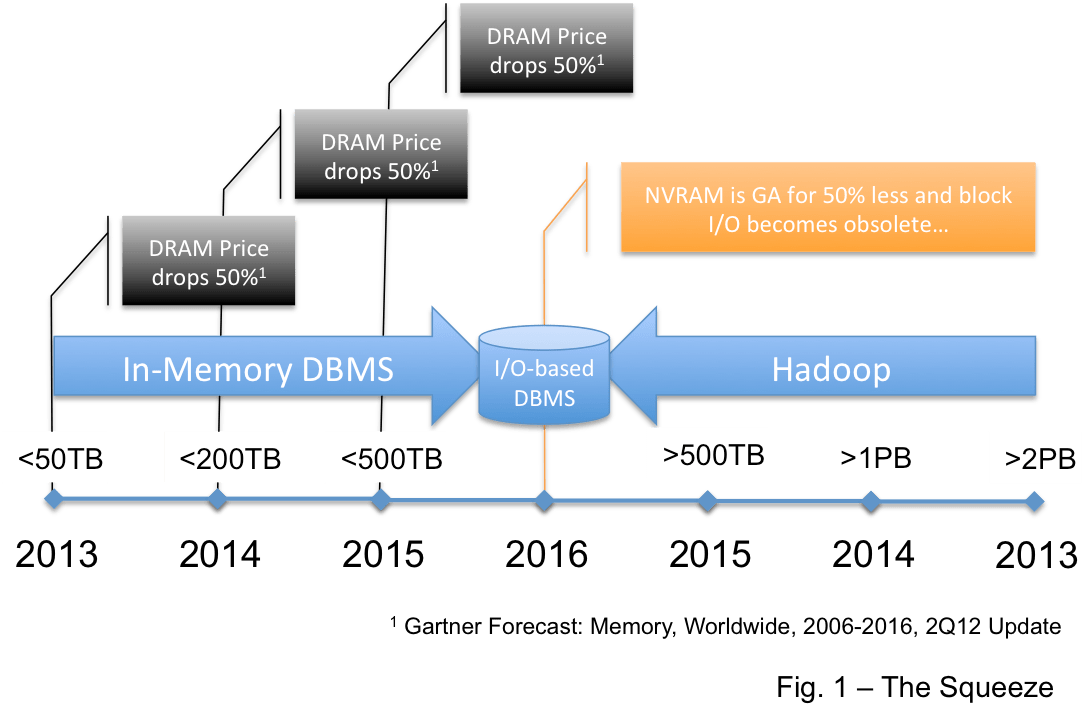
One place is in the data warehouse market… This view says Hadoop replaces the DBMS for data warehouses. But the very mature BI/DW market requires a high level of operational integrity and Hadoop is not there yet… it is advancing rapidly as an enterprise platform and I believe it will get there… but it will be 3-4 years. This is the thinking I provided here that leads me to draw the picture in Figure 1.
It is not that I believe that Hadoop will consume the data warehouse market but I believe that very large EDW’s… those over 1PB… and maybe over 500TB will be compelled by the economics of “free” to move big warehouses to Hadoop. So Hadoop will likely move down into the EDW space from the top.
Another option suggests that Big Data will be a platform unto itself. In this view Hadoop will sit beside the existing BI/DW platform and feed that platform the results of queries that derive structure from unstructured data… and/or that aggregate Big Data into consumable chunks. This is where Hadoop sits today.
In data warehouse terms this positions Hadoop as a very large independent analytic data mart. Figure 2 depicts this. Note that an analytics data mart, and a Hadoop cluster, require far less in the way of operational infrastructure… they share very similar technical requirements.
This leads me to the point of this post… if Hadoop becomes a very large analytic data mart then where will Greenplum and Netezza fit in 2-3 years? Both vendors are positioning themselves in the analytic space… Greenplum almost exclusively so. Both vendors offer integrated Hadoop products… Greenplum offers the Greenplum database and Hadoop in the same hardware cluster (see here for their latest announcement)… Netezza provides a Hadoop connector (here). But if you believe in Hadoop… as both vendors ardently do… where do their databases fit in the analytics space once Hadoop matures and fully supports SQL? In the next 3-4 years what will these RDBMSs offer in the big data analytics space that will be compelling enough to make the configuration in Figure 3 attractive?
I know that today Hadoop cannot do all that either Netezza or Greenplum can do. I understand that Netezza has two positions in the market… as an analytic appliance and as a data mart appliance… so it may survive in the mart space. But the overlap of technical requirements between Hadoop and an analytic data mart… combined with the enormous human investment in Hadoop R&D, both in the core and in the eco-system… make me wonder about where “Big Data” analytic relational databases will fit?
Note that this is not a criticism of the Greenplum RDBMS. Greenplum is a very fine product, one of the best EDW platforms around. I’ll have more to say about it when I provide my 2 Cents… But if Figure 2 describes the end state for analytics in 2-3 years then where is the place for the Figure 3 architecture? If Figure 3 is the end state then I do not see where the line will be drawn between the analytic workload that requires Greenplum and that that will run on Hadoop? I barely can see it now… and I cannot see it at all in the near future.
Both EMC Greenplum and IBM seem to strongly believe in Hadoop… they must see the overlap in functionality and feel the market momentum of Hadoop. They must see, better than most, that Hadoop wins this battle.
@henryccook made an interesting point regarding Netezza workload management this morning… He suggested that once a SPU is engaged by a snippet the work must be completed before another snippet can start. To say this another way… a SPU has no OS and cannot save context for a snippet and start another… then return.
If this is true it means that if a long-running snippet starts… a full file scan of a fact table with no use of the zone map… then that snippet will lock out others queries until it completes.
This is not a very fine-grained approach to workload management and we would expect it to cause difficulties.
Can anyone confirm that this is true? It feels right from an architectural perspective…
As you look at the enterprise RDBMS marketplace today you will find something shocking… almost every product in the market is built based on designs and concepts that are over thirty years old. IBM’s System R grew into DB2 and influenced Oracle before 1980. Ingres, developed before 1980, became Postgres which became Netezza and Greenplum and more. Teradata was a fresh start… around 1980.
This is not a bad thing in its own right… but imagine the hardware architectures these systems were designed and optimized for. Maybe DB2 was built for a multi-core mainframe… maybe Oracle too… maybe. Memory was tiny… so memory management was important and memory was used sparingly. Data sizes were tiny. Consider the fact that Teradata named the company based on the belief that someday way beyond the planning horizon some customers might get to a terabyte of data.
The reality is that these old designs are inefficient. They have hacked the old code to continuously extend their products. I mean this as a compliment. It is not trivial engineering to find tweaks and tack-ons that make old code work on new hardware architectures. Teradata and Netezza and Greenplum designed ways to use multiple address spaces to take advantage of multiple cores. Oracle tacked-on a shared-nothing I/O subsystem to a shared-everything architecture to stretch.
But these hacks are not efficient.
Yale is working on some new-new stuff (see here). HANA is based on a completely different design (see here). The NoSQL vendors have bent the ACID-tested rules, if not always the fundamental approaches.
I can’t help but believe that in one of these new approaches is a path forward.
If you would like to read some history of the start here is a cool link.
In my first blog (here) I discussed the implications of using co-processors to offload CPU. The point was that with multi-core processors it made more sense to add generalized processing hardware that could be applied to all parts of the query process than to add specialized processors that dealt with only part of the problem.
Kevin Closson has produced two videos that critically evaluate the architecture of Exadata and I strongly suggest that you view them here before you go on with this post… They are enlightening, irreverent, and make the long post I’ve been drafting on Exadata lightweight and unnecessary.
If you have seen Kevin’s post you understand that Exadata is asymmetric and unbalanced. But his post extends and generalizes my discussion of co-processing in a nice way. Co-processing is asymmetric by definition. The co-processor is not busy after it has executed on its part of the problem.
In fact, Oracle has approximately mirrored the Netezza architecture with Exadata but used commercial processors instead of FPGAs to offload I/O and predicate processing. The result is the same in both cases… underutilized processing capability. The difference is that Netezza wastes some power on relatively inexpensive FPGA processors while Exadata wastes general and expensive CPU resources that might actually be applied usefully elsewhere. And Netezza splits the processing within a shared-nothing architecture while Exadata mixes architectures adding to the inefficiency.
At this time of the year bloggers everywhere look back and reflect. Some use the timing to highlight significant achievements… and it is in the spirit that I would like to announce my choice for the best marketing in the data warehouse vendor space for 2011.
Marketing is a difficult task. Marketeers need to walk a line between reality and bull-pucky. They need to appeal to real and apparent needs yet differentiate. Often they need to generate spin to fuzz a good story by a competitors marketing or to de-emphasize some short-coming in their own product line.
Below is a picture taken on the floor of a prospect where we engaged in a competitive proof-of-concept. The customer requested that vendors ship a single rack configuration… and so we did.
But the marketing coup is that the vendor on the right, Teradata, told the customer that this is a single rack configuration and that they are in compliance. The customer has asked us if this is reasonable?
This creative marketing spin wins the 2011 award going away… against very tough competition.
I expect this marketing approach to start a trend in the space. Soon we will see warehouse appliance vendors claiming that 1TB = 50TB due to compression… or was that already done this year?
Sorry to be cynical… but I hope that the picture and story provide you with a giggle… and that the giggle helps you to start a happy holiday season.
So far this blog has focused on issues related to database architecture… so this title might not seem on message. But architecture has implications.
The aim of any BI system is to support the decision-making process of the business. BI infrastructure is clearly a success when your company learns to make fact-based decisions as part of the day-to-day operation of the business. The best data warehouse in the world would be one that provides such effective decision support that the business gains a competitive advantage over the competition.
But I often run into companies where sweet success has turned sour. Why, because in these sour situations the BI eco-system cannot keep up. In these bad cases the best data warehouse in the world becomes the worst.
Usually the problem comes in one of two flavors: either the required decision support is unavailable in time to make a decision, or the eco-system cannot extend to support new business opportunities.
The first case usually shows up during periods when decision-making increases: during seasonal peaks in business. The second appears when the business grows: after a merger or when a new product is introduced. In both cases the cost of the failure is significant.
But these worst cases do not happen out of the blue. They creep up on you. There are symptoms. Often the first symptom is when the nightly reporting process starts missing its service level targets. That is, the nightly load of the warehouse and the refresh of the indexes, materialized views, the summary tables, the cubes, and the marts; and then the running of reports cannot complete in the batch window. This is followed by slow response in your online query processing as the nightly process creeps into the day. Then, the business asks for more users and/or for more data to be added and the problem grows… until decision-making is delayed or unsupported altogether.
Sadly, this problem is avoidable and the solution is well understood. All that is required is a scalable foundation that can extend through the addition of relatively inexpensive hardware. If you could easily add storage and compute then as the constraints hit you can scale up.
A shared nothing architecture scales. We have examples at Greenplum of production systems that scale from hundreds of gigabytes to thousands of terabytes… and other shared nothing vendors: Teradata and Netezza at least, can boast the same. When our customers run out of gas we add hardware. And the architecture scales bigger still… shared nothing is the foundation for all web scale data base technology… scaling to hundreds of petabytes.
So why do companies build, and continue to build, on shared memory systems with built-in limits? Because… they continually underestimate the growth in data… the failure is a failure of vision (consider the name “Teradata”… selected when a terabyte was considered nearly unreachable). Data does not just grow, it explodes in leaps and bounds as technology advances.
But let’s be real… Why do companies really select limiting infrastructure? Because they mistakenly believe that they can build BI infrastructure on technology designed for OLTP… and they already have DBAs trained on this technology who heavily influence the decision. Or, they have an enterprise license for the OLTP database and they want to save some money.
I imagine that I’ve made my point. The worst data warehouse in the world is a warehouse that constrains your business… one that cannot scale as the demand for data and decision support grows… one that costs you hundreds of thousands of dollars in staff time with every change… one that is tuned to the breaking point, rather than robust.
Why would anyone ever put their business at risk like this?